RESEARCH PROGRAM

Title: Visualization and Analytics for Supercomputing Performance Data
Name: Alfredo Giménez, PhD
(former student)
Project description:
Optimizing applications in high-performance computing environments requires extensive analysis and visualization of performance-related data. Traditionally, this data includes hardware counters, program traces, and sampling/profiling data. I am exploring ways to expand upon traditionally acquired performance data to include more high-level information such as program phases and scientific data. This allows users to ask more intuitive analysis questions, and it also enables analysis methods that diagnose problems, rather than simply show data. Furthermore, there exist a variety of data sources outside of the supercomputing systems themselves that are becoming of high interest, particularly energy consumption. I am extending my work in attribution of high-level data to also find relationships between performance data and energy consumption data acquired at the supercomputing facility.
Starting Situation
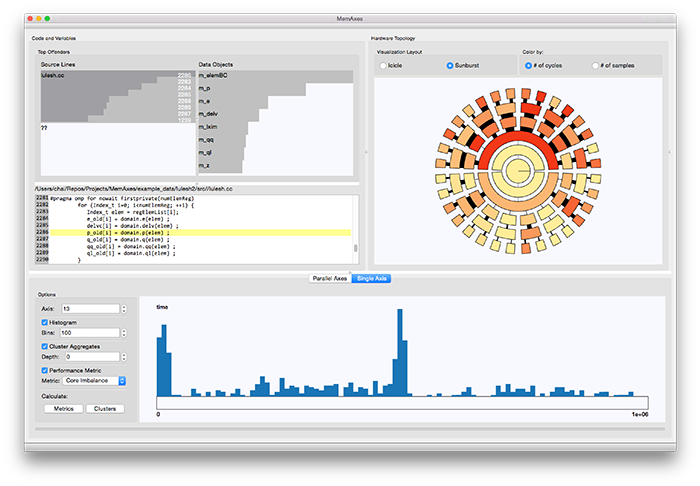
We have successfully developed methods for attributing high-level context to low-level performance data by creating an in-memory context tree whose information is appended to incoming data streams. As a result, hardware counters and samples have an associated program state, including program phase, iteration, and active variables. However, the resulting data is often too large to fit into memory for analysis.
Secondly, we have access to a wide array of facility-level data including output from temperature sensors and energy consumption in the high-performance computing facility. This data is temporally defined but there still remains a loose correlation between it and application-level data.
Approach
We set up a distributed database to store large quantities of performance data using HBase. This allows for both scalable storage and scalable queries using MapReduce-style queries. I am currently developing a library for interacting with this database, allowing for analysis-driven questions. This library will parse an analysis question into a database query and set up a MapReduce-style operation to gather the response. Questions may include: how many cache misses occurred during a specified program phase, or how much did the temperature of the system increase for a given workload. These questions require filtering, aggregation, and projection operations, which will be executed transparently to the user.
Expected Results
We expect to find a strong positive correlation between temperature and energy consumption in the facility—cooling units dynamically adjust for the facility temperature, which requires significantly more power. However, we do not know what program variables will correlate most with temperature. CPU frequency will undoubtedly have an effect, but little is known of how the other subsystems affect temperature, such as message passing and memory access. We hope to find the causes for temperature and in turn energy consumption so that we can develop more energy-efficient high-performance computing solutions.